OWL Best Practices: Using Enumerated Classes to Define Ordered Values
- Michael DeBellis

- Oct 15, 2019
- 3 min read
Updated: Jun 26, 2020
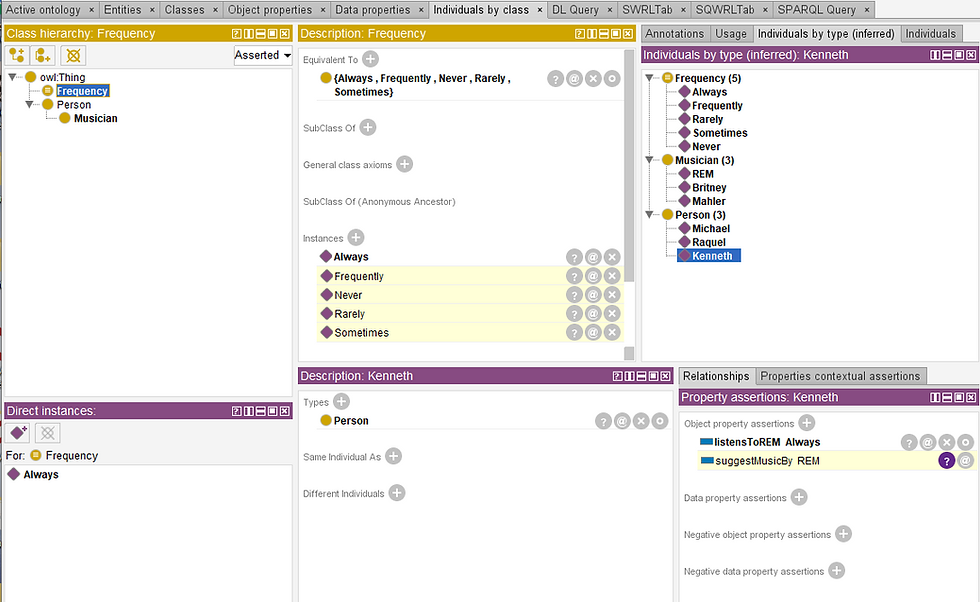
One question I often see on the Protege user mailing list goes something like this: "I have a property that takes on values such as never, rarely, sometimes, frequently and always. Is it better to implement this as a string data property or as an object property?". As with most modeling questions there is never a definitive answer. If you are constrained by some existing applications you may need to implement such properties as strings. However, in most cases I think the better answer is to create an enumerated class. An enumerated class is a defined class where all the possible instances are known and are used to define the class. So in this case we could define a class called Frequency. We would create five individuals that correspond to each possible frequency: Never, Rarely, etc. and in the Frequency class's EquivalentTo field type the DL statement: {Never, Rarely, Sometimes, Frequently, Always}.
In set theory it is possible to define a set implicitly by a logical statement (e.g., the set of all natural numbers greater than or equal to 1 and less than or equal to 5) or explicitly (e.g., the set {1,2,3,4,5}). Using DL definitions in OWL corresponds to the implicit definition of a set and using enumerated definitions corresponds to the explicit definition. There are several advantages to using enumerated classes rather than strings. For one thing in Protege whenever we want to refer to a frequency value if we make it an enumerated class we can always use control-<space> to complete what we have typed (e.g., in a rule or DL statement). Also, when we compare values rather than strings, we don't have to worry about whether "Never" is the same as "never" or "NEVER".
One of the most powerful advantages is when we have examples such as Frequency where the values can be put into an order. In this case we can define object properties such as isMoreFrequentThan and its inverse isLessFrequentThan. We can make these properties transitive. I.e., if x isMoreFrequentThan y and y isMoreFrequentThan z then x isMoreFrequentThan z. Once we do this all we need to do is to define the basic ordering, e.g., that Always isMoreFrequentThan Frequently; Frequently isMoreFrequentThan Sometimes; Sometimes isMoreFrequentThan Rarely and Rarely isMoreFrequentThan Never. Once we have those values asserted the reasoner can infer the rest based on the fact that isLessFrequentThan is the inverse of isMoreFrequentThan and that the properties are transitive. In fact we don't even need to define that isLessFrequentThan is transitive, the reasoner will also infer that since it is the inverse of isMoreFrequentThan and isMoreFrequentThan is transitive.
This enables us to do tests in rules and DL statements such as: isMoreFrequentThan(?f, Sometimes)
The following Frequency Example Ontology provides a sample ontology that implements these ideas. There are 3 rules that test to see if a customer listens to a specific artist more frequently than sometimes and if so suggests additional music by that artist. One example rule is: listensToREM(?p, ?f) ^ isMoreFrequentThan(?f, Sometimes) -> suggestMusicBy(?p, REM). Note that in this version of the ontology there needs to be a specific rule for each artist. This is not good design. A better design would be to have the relation that indicates how frequently one listens to an artist be a a ternary rather than a binary relation. I.e., not a relation that records the customer and the frequency but rather the customer, the artist, and the frequency. OWL does not support anything but binary relations however it is possible to use a common design pattern to implement ternary (or N-ary) relations. That is the topic of my next post.
Comments